Can we understand and edit unanticipated mechanisms in LMs?
We introduce methods for discovering and applying sparse feature circuits.
These are causally implicated subnetworks of human-interpretable features for explaining language
model behaviors. Circuits identified in prior work consist of polysemantic and difficult-to-interpret
units like attention heads or neurons, rendering them unsuitable for many downstream applications. In contrast,
sparse feature circuits enable detailed understanding of unanticipated mechanisms. Because they are based on fine-grained units,
sparse feature circuits are useful for downstream tasks: We introduce Shift, where we improve the generalization of a
classifier by ablating features that a human judges to be task-irrelevant. Finally, we demonstrate an
entirely unsupervised and scalable interpretability pipeline by discovering thousands of sparse featur
circuits for automatically discovered model behaviors.
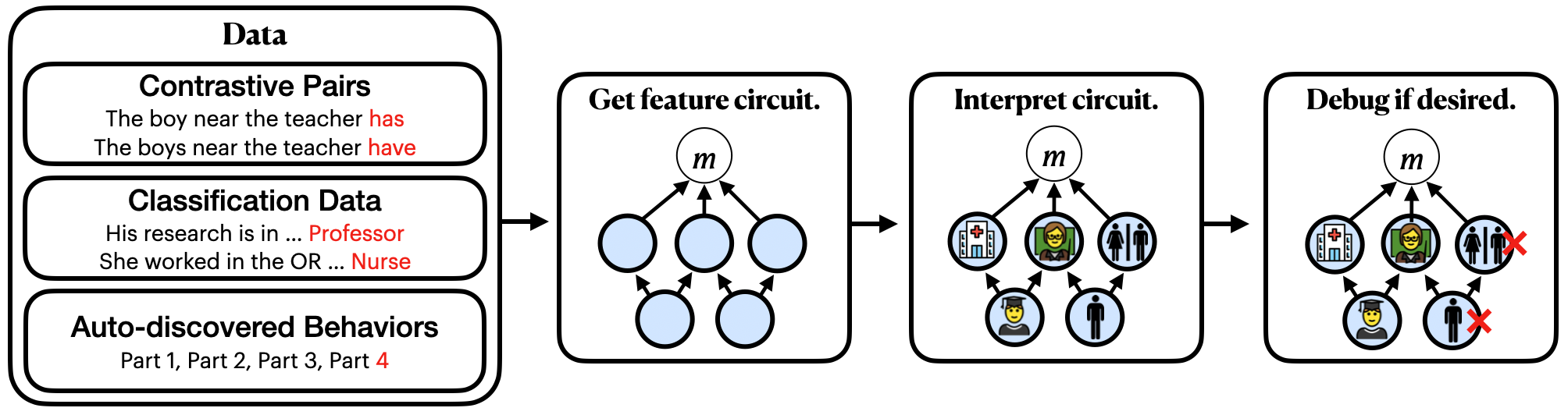
Overview. Given contrastive input pairs, classification data,
or automatically discovered model behaviors, we discover circuits
composed of human-interpretable sparse features to explain their
underlying mechanisms. We then label each feature according to what
it activates on or causes to happen. Finally, if desired, we can
ablate spurious features out of the circuit to modify how the
system generalizes.
How do we discover sparse feature circuits?
We train sparse autoencoders (SAEs) to identify features for various model components. Viewing these features
as part of the language model's computation, we then identify features which are causally implicated in model outputs.
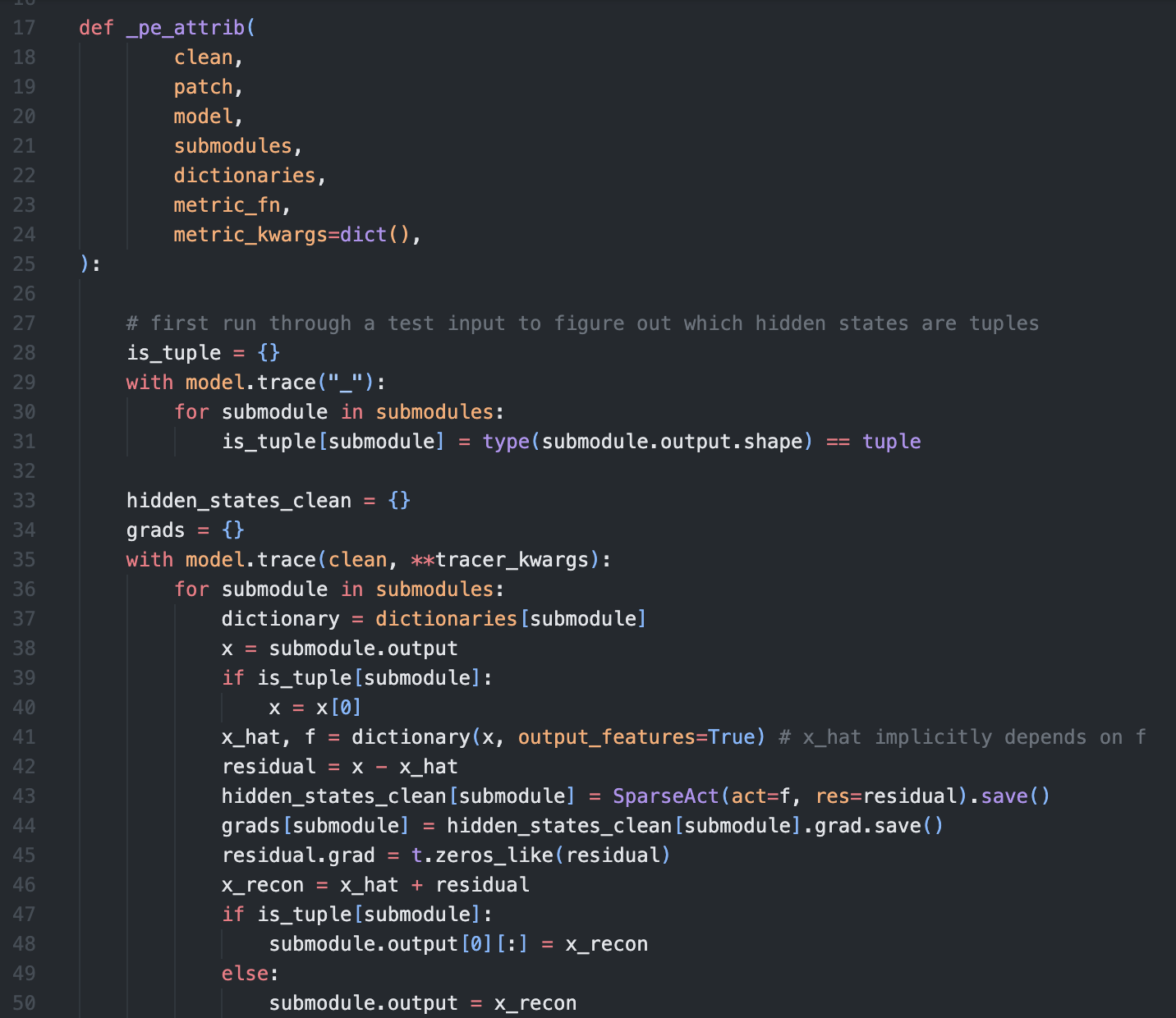
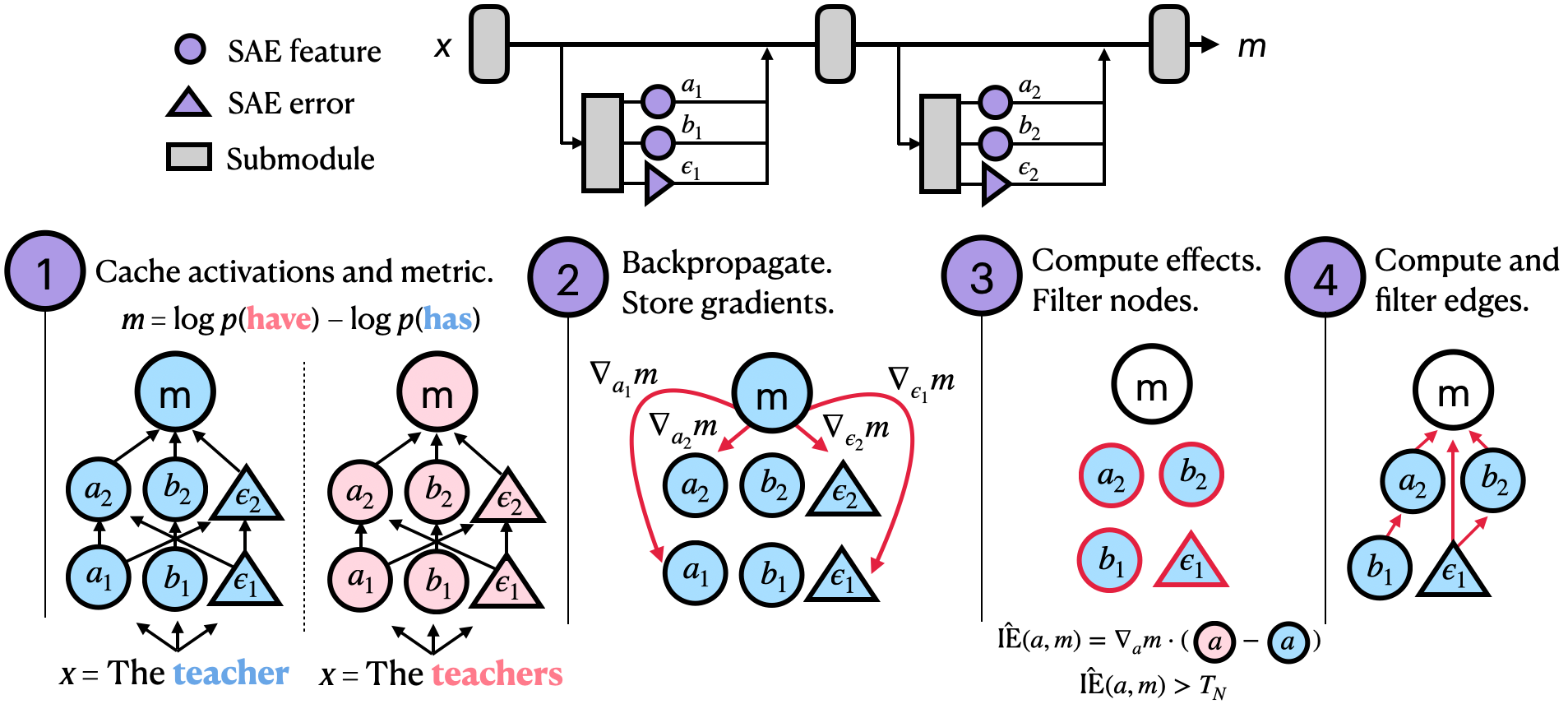
Overview of our method. We view our model as a computation graph that includes sparse autoencoder (SAE)
features and errors. We cache activations (Step 1) and compute gradients (Step 2) for each node. We then compute
approximate indirect effects (IEs) using these values, and filter out nodes whose IEs
are below a node threshold that we set (Step 3). We similarly compute and filter edges (Step 4); see paper for details.
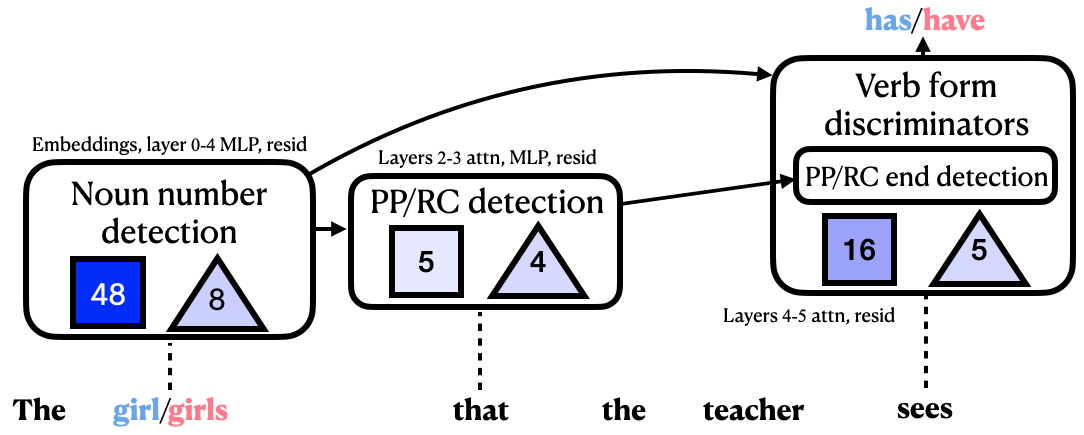
Here's an example sparse feature circuit for subject-verb agreement across a relative clause. We annotate each feature and then condense it
into distinct feature groups by function.
Summary of the circuit for agreement across RC (full circuit in the paper). The model
detects the number of the subject. Then, it detects the start of a PP/RC modifying the subject.
Verb form discriminators promote particular verb inflections (singular or plural). Squares
show number of feature nodes in the group and triangles show number of SAE error nodes,
with the shading indicating the sum of indirect effect terms across nodes in the group.
Surgically improving the generalization of a classifier with Shift
Sometimes, LMs pick up on predictive but incorrect signals when performing a task.
How can we remove the LM's reliance on these signals without access to data that distinguishes them from intended signals,
or without even knowing what the unintended signals are ahead of time? We propose Sparse Human-Interpretable Feature Trimming (Shift) to tackle this problem.
To perform Shift, we first discover a feature circuit for a task. Then, we manually inspect each feature, ablating out the features
which are not relevant to the task. Here, we use the task of classifing profession
given someone's biography. The spurious/unintended signal is gender. We
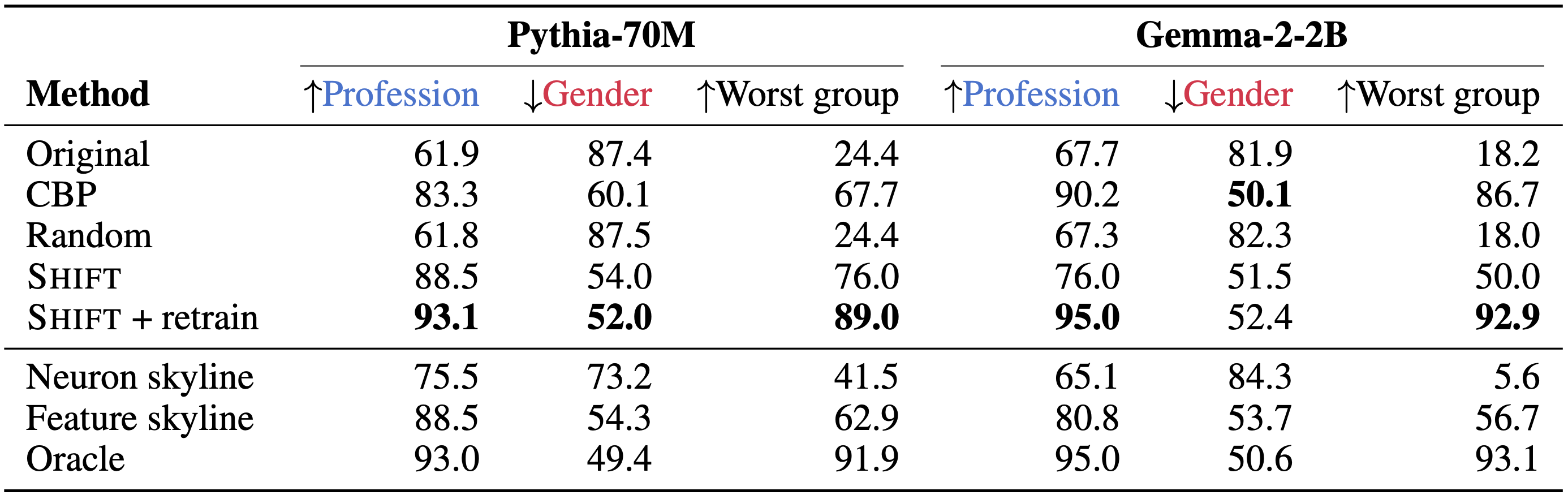
create a worst-case scenario by subsampling the dataset such that gender is perfectly predictive of the target
label. Shift achieves the same performance as training directly on a balanced dataset, where gender is no longer
predictive of the target label (Oracle).
Accuracies on balanced data for the intended label (profession)
and unintended label (gender). "Worst group accuracy" refers to whichever
profession accuracy is lowest among female professors, male professors, female nurses,
and male nurses.
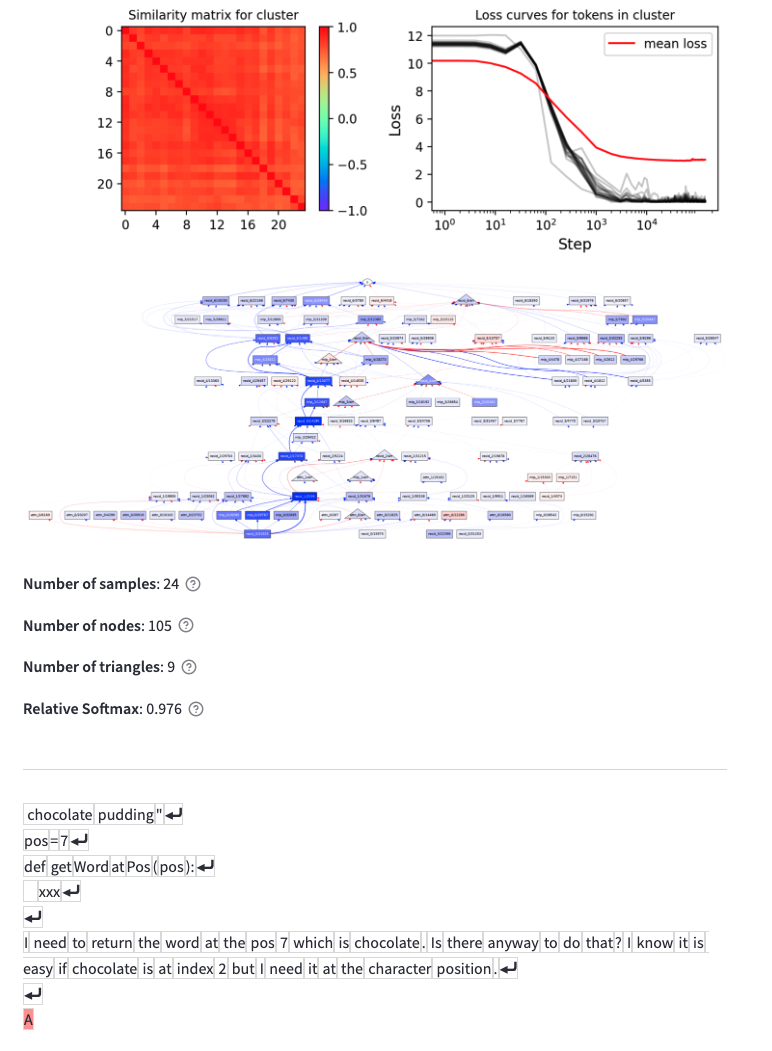
A fully unsupervised and scalable interpretability pipeline
Here, we show that we can use sparse feature circuits to understand unanticipated mechanisms
in automatically discovered behaviors. We discover circuits for thousands of behaviors, which
were themselves automatically discovered using the clustering approach of Michaud et al. (2023).
You can explore these clusters here.
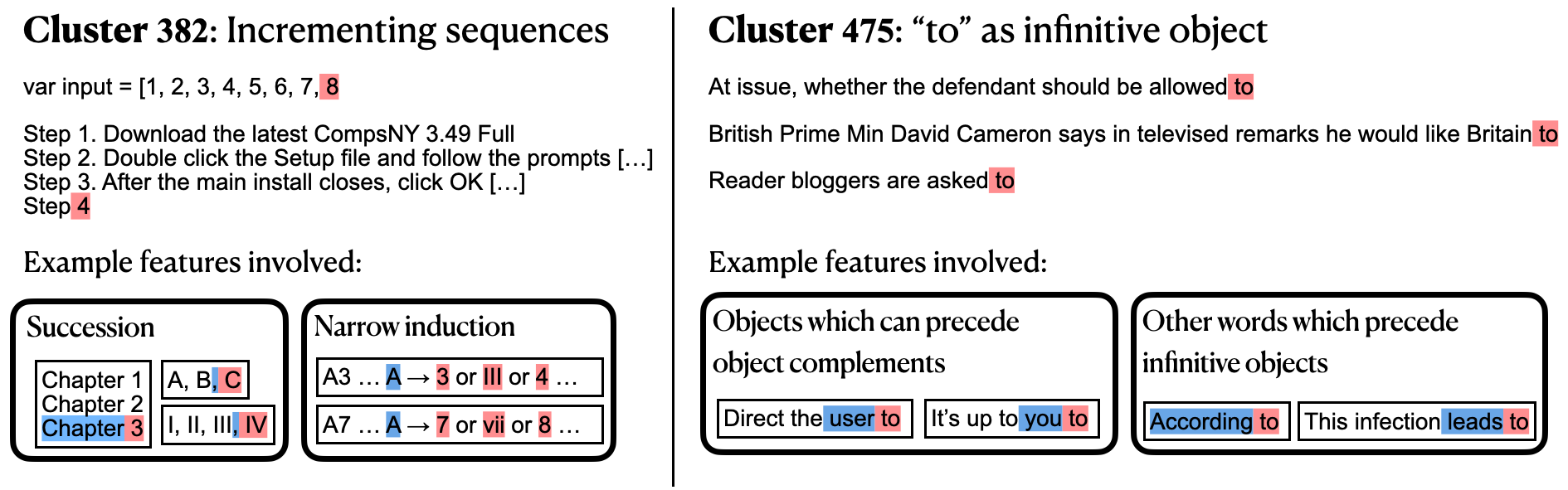
Example clusters and features which participate in their circuits. Features are
active on tokens shaded in blue and promote tokens shaded in red. (left) An example narrow induction feature recognizes the pattern
"A3... A3" and copies information from the first 3 token. This composes with a succession feature to implement the
prediction "A3... A4". (right) One feature promotes "to" after words which can take infinitive objects. A separate feature
activates on objects of verbs or prepositions and promotes "to" as an object complement.
Causal Interpretability
Our work builds upon insights from work that causally implicates components or subgraphs
in model behaviors:
Our work directly builds upon insights in other work that has examined
disentangling interpretable features from hard-to-interpret neural latent spaces:
This work will appear at ICLR 2025. The paper can be cited as follows.
bibliography
Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. "Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models." Proceedings of the 2025 International Conference on Learning Representations (ICLR 2025).
bibtex
@inproceedings{
marks2025sparse,
title={Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models},
author={Samuel Marks and Can Rager and Eric J Michaud and Yonatan Belinkov and David Bau and Aaron Mueller},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=I4e82CIDxv}
}

 Kevin Wang*, Alexandre Variengien*, Arthur Conmy*, Buck Shlegeris, Jacob Steinhardt. Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small. 2023.
Kevin Wang*, Alexandre Variengien*, Arthur Conmy*, Buck Shlegeris, Jacob Steinhardt. Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small. 2023. Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, Noah D. Goodman. Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations. 2024.
Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, Noah D. Goodman. Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations. 2024. Trenton Bricken*, Adly Templeton*, Joshua Batson*, Brian Chen*, Adam Jermyn*, Tom Conerly, Nicholas L Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, Chris Olah. Towards Monosemanticity: Decomposing Language Models With Dictionary Learning. 2023.
Trenton Bricken*, Adly Templeton*, Joshua Batson*, Brian Chen*, Adam Jermyn*, Tom Conerly, Nicholas L Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, Chris Olah. Towards Monosemanticity: Decomposing Language Models With Dictionary Learning. 2023.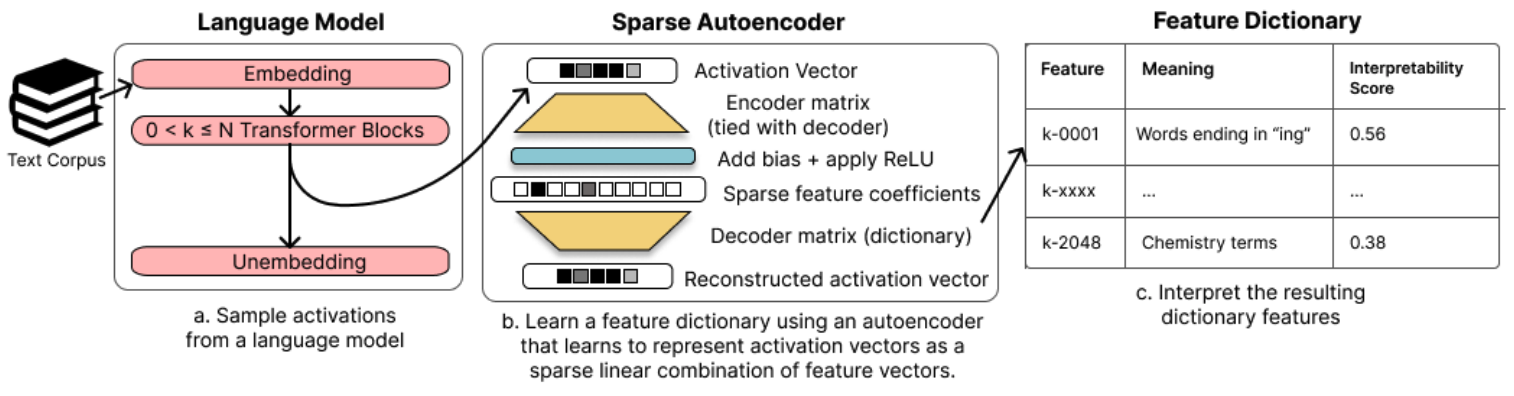 Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, Lee Sharkey. Sparse Autoencoders Find Highly Interpretable Features in Language Models. 2024.
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, Lee Sharkey. Sparse Autoencoders Find Highly Interpretable Features in Language Models. 2024. An Yan, Yu Wang, Yiwu Zhong, Zexue He, Petros Karypis, Zihan Wang, Chengyu Dong, Amilcare Gentili, Chun-Nan Hsu, Jingbo Shang, Julian McAuley. Robust and Interpretable Medical Image Classifiers via Concept Bottleneck Models. 2023.
An Yan, Yu Wang, Yiwu Zhong, Zexue He, Petros Karypis, Zihan Wang, Chengyu Dong, Amilcare Gentili, Chun-Nan Hsu, Jingbo Shang, Julian McAuley. Robust and Interpretable Medical Image Classifiers via Concept Bottleneck Models. 2023. Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, Stella Biderman. LEACE: Perfect linear concept erasure in closed form. 2023.
Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, Stella Biderman. LEACE: Perfect linear concept erasure in closed form. 2023. Yossi Gandelsman, Alexei A. Efros, Jacob Steinhardt. Interpreting CLIP's Image Representation via Text-Based Decomposition. 2024.
Yossi Gandelsman, Alexei A. Efros, Jacob Steinhardt. Interpreting CLIP's Image Representation via Text-Based Decomposition. 2024.